
Performance Comparison of Large Language Models in Dentistry: A Focus on Restorative Dentistry Using Turkish Specialty Exam Questions
DOI:
https://doi.org/10.5281/zenodo.18585386Keywords:
Artificial Intelligence, Dental Education , Large Language Models , Restorative DentistryAbstract
Objectives: This study aimed to comparatively evaluate the accuracy, response time, and content length of five large language models (LLMs), ChatGPT-4o, ChatGPT-o3-mini, Deepseek-v3, Google Gemini 2.0 Flash, and Microsoft Copilot, based on restorative dentistry questions from the Turkish Dental Specialty Exam (DUS).
Materials and Methods: A total of 100 multiple-choice questions from the restorative dentistry sections of the DUS (2016–2024) were presented to each LLM model in Turkish under standardized testing conditions. Model performance was assessed based on three primary metrics: answer accuracy, response generation time, and content length (word count). Temporal consistency was evaluated by re-submitting a 10% sample after two weeks. Statistical analyses were conducted to compare differences among the models.
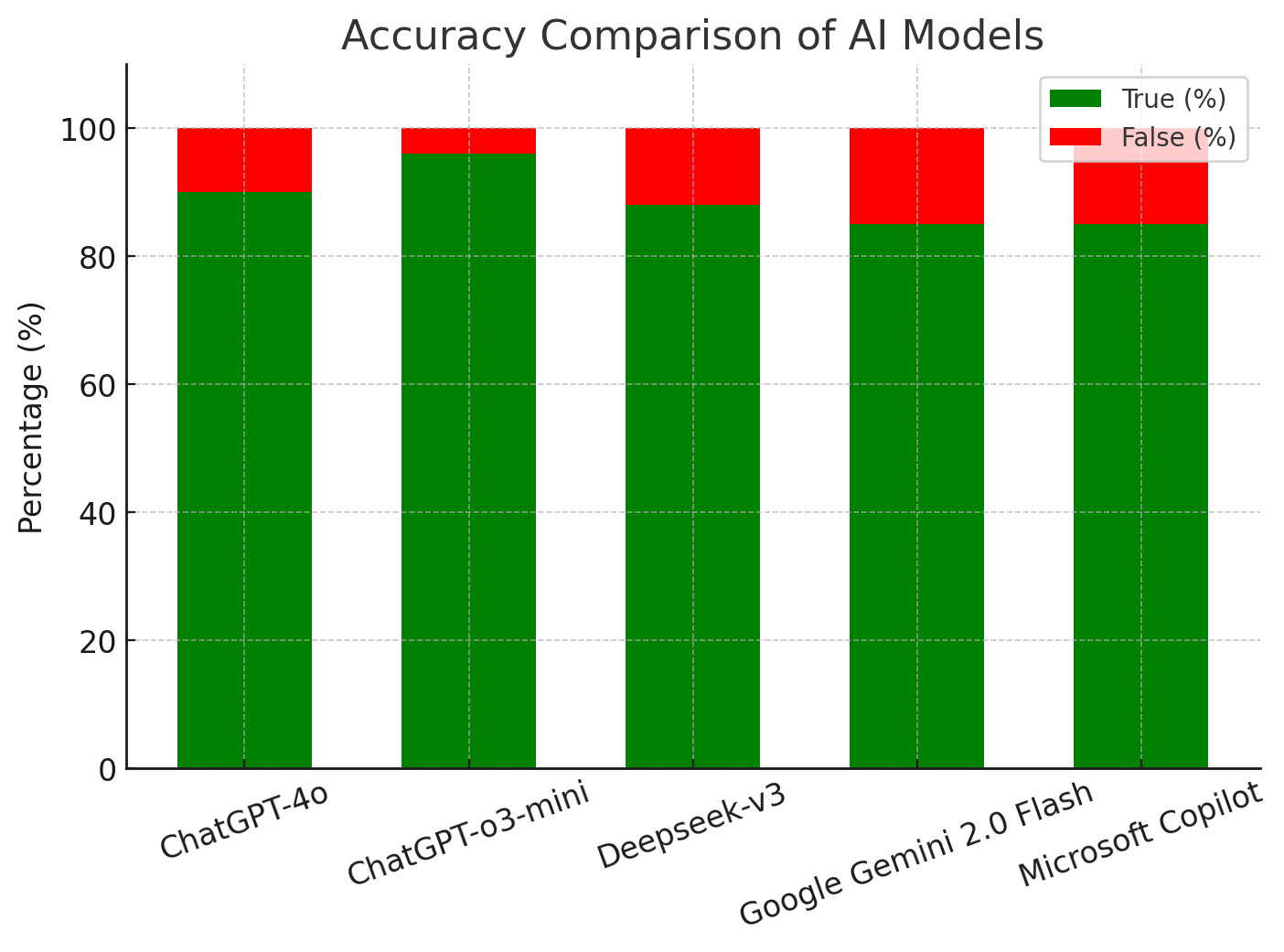
Results: ChatGPT-o3-mini achieved the highest accuracy (96%), followed by ChatGPT-4o (90%), Deepseek-v3 (88%), and both Gemini and Copilot (85%). Microsoft Copilot was the fastest model (median: 3.19 s), while Deepseek-v3 was the slowest (median: 25.64 s). Google Gemini 2.0 Flash produced the longest responses (median: 218 words), whereas Microsoft Copilot generated the shortest (median: 34 words).
Conclusion: LLMs demonstrate promising potential for supporting dental education, particularly in restorative domains. Among the evaluated models, ChatGPT-o3-mini showed the highest overall accuracy, suggesting its relative suitability for knowledge-based tasks in dentistry. However, performance varied by model and topic, indicating that no single system is universally superior. Model selection should be guided by the intended application, whether speed, depth, or accuracy is prioritized. The use of standardized specialty exam questions offers a reliable framework for benchmarking LLM performance in domain-specific contexts.
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2026 Muhammed Baytar, Fatma Pertek Hatipoğlu

This work is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.
CC Attribution-NonCommercial 4.0







